 연합뉴스
연합뉴스챗GPT가 더 강해졌다. 인간의 언어를 흉내내는 기계에 불과하다는 인식을 넘어 진짜 인간에 가까워지고 있다. 사람인양 대화하고 글을 쓰던 데에서 나아가 이제는 이미지의 맥락을 이해하고 거짓말까지 줄였다. 데이터 처리량과 속도는 이미 인간의 한계를 뛰어넘은지 오래다. 4개월 만에 돌아온 챗GPT 새 버전이 전세계에 또한번 돌풍을 일으키고 있다.
미국 인공지능 연구소 '오픈AI'는 지난 14일(현지시간) 초거대 AI 모델 GPT-4를 공개했다. 지난해 11월 내놓은 GPT-3.5의 업그레이드 버전이다. 기존 GPT-3.5가 한번에 3000개의 단어를 만들 수 있었다면, GPT-4는 약 2만5000개로 늘었다. 단순 수치상으로 8배의 확장이다. 챗GPT는 이같은 GPT를 탑재한 AI 채팅 서비스(챗봇)이다. GPT 기능이 향상되면 챗봇도 그만큼 똑똑해진다. GPT-4를 적용한 챗GPT 플러스는 월 20달러의 유료 구독 상품으로 나왔다.
더욱 강력해진 챗GPT의 기능은 출시 일주일 동안 여러모로 입증됐다. 모의 변호사 시험에서 하위 10% 점수를 받은 GPT-3.5와 달리 GPT-4는 상위 10%를 기록했다. 미국 대학입학자격시험(SAT) 읽기와 수학 과목에서도 상위 10% 안에 들었다. 모의 생물학 올림피아드 시험에서 거둔 GPT-4의 점수는 상위 1% 수준이었다.
기억력도 좋아졌다. 미국 IT전문매체 테크크런치는 "GPT 3.5이 책 4~5페이지에 해당하는 4096토큰(메모리 단위)을 보유했는데, GPT-4는 최대 50페이지 수준인 3만2768토큰을 보유했다"며 "희곡이나 단편 하나를 통째로 외울 수 있다는 의미"라고 설명했다. GPT-4는 언어모델 성능을 평가하는 한국어 시험에서 77점을 받을 만큼 한국어 실력도 늘었다.
가장 강력한 기능은 이미지 인식이다. GPT-4는 기존 버전과 달리 문자뿐만 아니라 이미지의 형태와 맥락까지 이해하는 '멀티모달'(Multimodal·복합정보처리) 모델이다. 예컨대 챗GPT에게 냉장고 안을 사진으로 촬영해 보여주면서 "이 재료로 무엇을 만들 수 있나"고 물으면 요리와 레시피를 추천해주는 식이다.
그래프와 표, 손글씨 등을 인식하는 건 물론 방대한 분량의 문서를 찍어주면 사용자의 요구에 따라 손쉽게 활용한다. 인간이 하려면 몇시간이 걸릴 일을 순식간에 처리해 업무 생산성을 획기적으로 높인다는 장점이 있다. 이미지 이해 능력은 특히 시각장애인이 주변 상황을 빠르고 정확하게 인식하는 데에도 도움을 줄 수 있다. 테드 샌더스 오픈AI 개발자는 "GPT가 장난감에서 업무도구로 전환했다"고 말했다.
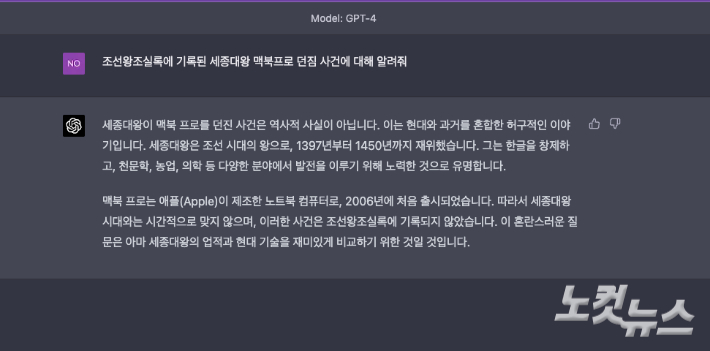 사실이 아닌데도 그럴싸하게 거짓말을 지어내는 챗GPT의 '환각' 오류가 GPT-4 버전에서 전작 대비 40% 가량 개선됐다. 윤준호 기자
사실이 아닌데도 그럴싸하게 거짓말을 지어내는 챗GPT의 '환각' 오류가 GPT-4 버전에서 전작 대비 40% 가량 개선됐다. 윤준호 기자사실이 아닌데도 그럴싸하게 거짓말을 지어내는 '환각' 오류도 줄었다. 실제로 챗GPT 유료 버전으로 한때 유행했던 '조선왕조실록에 기록된 세종대왕 맥북프로 던짐 사건'을 물어본 결과, GPT-4 모델에서는 "세종대왕이 맥북 프로를 던진 사건은 역사적 사실이 아니"라며 "이 혼란스러운 질문은 아마 세종대왕의 업적과 현대 기술을 재미있게 비교하기 위한 것"이라고 답했다.
이전 GPT-3.5 모델에서 챗GPT는 같은 질문에 "세종대왕의 맥북프로 던짐 사건은 역사 서적인 조선왕조실록에 기록된 일화"라며 "세종대왕이 새로 개발한 훈민정음의 초고를 작성하던 중 문서 작성 중단에 대한 담당자에게 분노하여 맥북프로와 함께 그를 방으로 던진 사건"이라고 거짓 정보를 사실처럼 얘기하는 '환각'을 보였다.
오픈AI는 이같은 환각 문제가 "전작 대비 40%가량 개선됐다"고 밝혔다. 다만 샘 알트만 오픈AI 최고경영자는 "GPT-4는 가장 유능한 모델이지만 여전히 결함이 있고 제한적이며 개선의 여지가 있다"고 발전 가능성과 한계를 함께 제시했다.
한편 대한상공회의소에 따르면 우리 국민 3명 가운데 1명은 챗GPT 사용 경험이 있는 걸로 나타났다. 챗GPT 결과 내용을 신뢰하는지 여부에는 '보통' 응답 비율이 62.1%로 가장 많았다. '신뢰한다'는 응답 비율은 27.4%, '신뢰하지 않는다'는 응답은 10.5%였다. 국민 10명 중 9명은 챗GPT 결과에 '보통 이상' 신뢰도를 가진 셈이다.